동시성 VS 병렬성
동시성
여러 작업이 중복된 시간 동안 한정된 리소스에 대한 경쟁을 하면서 실행되는 것
작업들을 스케쥴링 하고 작업 간 실행을 전환해가면서 동시에 실행되지는 않지만, 동시에 실행되는 것 처럼 보인다.
스레드 안전 (Thread-safe) 하게 설계 되어야 한다 (락, 세마포어 등)
병렬성
작업들이 동시에 실행되는 것
각각의 작업들이 병렬적으로 동시에 실행되는 것

병렬 스트림
중간 스트림 연산인 parallel 혹은 Collection 타입 기반에서 parallelStream 메서드를 통해 파이프 라인을 병렬 모드로 전환 할 수 있다.
다시 순차 스트림으로 돌아가려면 중간연산인 sequential을 사용하면 된다.
(다만 실행 모드 변경 시에는 파이프라인 위치에 관계없이 전체 파이프라인에 영향을 미친다. 최종 연산 전 마지막으로 호출 된 모드가 전체 파이프라인의 모드를 결정 지어, 일부만 다른 모드로 실행이 불가능 하다.)
재귀적 분해를 통해 요소를 Spliterator를 이용하여 요소의 덩어리로 분할 (Fork),
요소의 덩어리를 전용 스레드에 의해 병렬로 처리 (필요에 따라 재귀적으로 더 분할),
각 스레드의 결과들을 다시 합쳐 (JOIN) 최종 결과를 도출
형태로 병렬적으로 파이프라인을 실행한다.

이 과정에서 스트림 API 는 내부적으로 ForkJoinPool을 활용하여 새로운 스레드를 효과적으로 생성하고 관리한다.
*ForkJoinPool
작업 훔치기 방식으로 스레드를 실행 (한 스레드가 자신의 작업을 끝낸 후 다른 스레드가 아직 처리하지 못한 작업을 훔쳐와 실행)
런타임에서 자체적으로 관리하며 초기화가 지연되는 정적 스레드 풀
병렬 스트림과 CompletableFutures를 이용한 비동기 작업에서 활용된다.
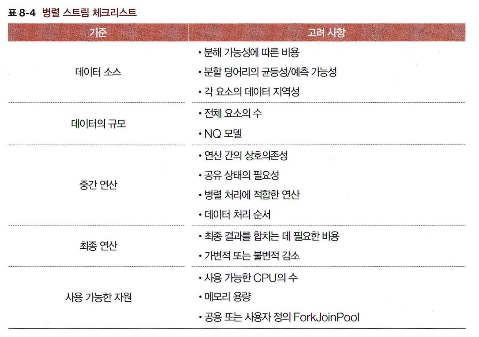
병렬 스트림 활용 시기와 주의할 점
적절한 데이터 소스
순차 스트림에서 Spliterator는 단순 반복자 역할을 하지만, 병렬 스트림에서는 데이터 소스를 분할하는 역할을 한다.
데이터 소스를 분해 할 때, 데이터 소스의 특성에 따라 비용의 차이가 발생한다.
데이터 소스의 크기를 정확히 알고 있고, 모든 요소들의 위치를 알고 있을 수록 쉽게 분해 가능하다.


또한 데이터 지역성도 병렬 스트림에 영향을 준다.
연속된 메모리 공간에 저장 될 수록 유리하고, 필요 값이 캐시에 없을 경우 리소스 낭비가 발생하게 된다.
다만, 기본 배열만이 병렬 처리에 적합하다는 뜻이 아니라, 다른 기준들에 대한 고려도 필요하다. (데이터 지역성은 다른 기준들에 비해서 상대적으로 중요도가 낮다)
요소의 개수
최적의 요소수는 명확히 정해져 있진 않다.
다만, 처리해야 할 요소가 많을 수록 성능 향상에 유리하다. (스레드 조정 오버헤드를 줄일 수 있기 때문)
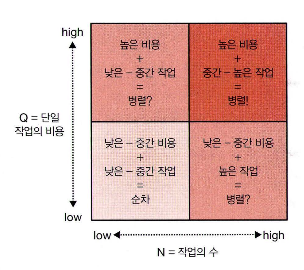
요소의 수가 많을 수록, 실행 시간이 긴 작업일수록 병렬 처리 시 큰 효과를 얻을 수 있다.
스트림 연산
순차 스트림과 동일한 결과를 얻기 위해, 병렬 스트림에서는 더 많은 함수적 원칙과 연산 방식을 준수해야 한다.
1) 순수한 람다
스트림 연산에서 사용되는 람다 표현식은 항상 순수해야 한다.
외부의 변경 가능 상태에 의존하거나, 사이드 이펙트를 발생시키면 안된다. (effectively final 상태)
스레드가 지역 외부의 상태를 변경할 때 문제가 발생 할 수 있다. (스레드 간 모든 접근은 동기화가 필요)
이를 방지하기 위해 가장 간단한 방법은 지역 외부의 상태를 깊게 불변하게 만드는 방법이 있다.
2) 병렬 처리에 적합한 연산
스트림 요소에 대한 접촉 순서에 의존하는 정도로 직관적으로 판단 할 수 있다.
limit, skip, distinct 같은 중간 연산은 접촉 순서에 많은 의존성을 갖고, 일관된 순서를 필요로 한다. (일관되고 안정된 결과를 보장하기 위해 추가 비용 필요)
중간 연산에 unordered연산을 호출하면 일관된 순서를 필요로 하지 않는다.
findAny나 forEach같은 연산은 요소와 순서에 제약을 받지 않아 큰 이점을 얻을 수 있다.
축소 연산
결합성 (누적기의 인수의 순서나 그룹화가 최종 결과에 영향을 미치치 않는 것)이 있고 공유 상태가 없다면 쉽게 병렬화 가능하다.
불변한 축소 방식이 병렬에 적합해도, 누적 단계마다 새로운 불변 결과를 생성하는 것이 비용이 더 발생 할 수 있다.
가변 축소는 가변 결과 컨테이너를 사용하여 위의 오버헤드를 효과적으로 줄인다.
스트림 오버헤드와 사용 가능한 자원
순차 스트림이든 병렬 스트림이든 전통 반복 구조와 비교했을 때 오버헤드가 발생한다.
병렬 스트림은 순차 스트림 보다 큰 제약을 감수해야 한다. (데이터 소스 분해 비용, ForkJoinPoll에 의한 스레드 관리, 스레드 결과 재조합 등...)
동시에 실행 가능한 병렬 작업의 수에 따라 최대 성능 향상에 한계가 있다.
아직 병렬 스트림을 언제 사용하고, 안전하게 사용하는 방법이 와닿지는 않는다.
직접 사용해보고, 순차 스트림과의 실행 속도 등을 비교해보면서 체험해야 감이 잡힐 것 같다.
'함수형 자바' 카테고리의 다른 글
| [JAVA] 함수형 예외 처리 - Chapter 10 (0) | 2024.07.04 |
|---|---|
| [JAVA] Optional을 사용한 null 처리 - Chapter 09 (0) | 2024.06.27 |
| [JAVA] 스트림 (Stream) - Chapter 06 (0) | 2024.06.03 |
| [JAVA] 레코드 (Record) - Chapter 05 (0) | 2024.06.02 |
| [JAVA] 불변성 - Chapter 04 (0) | 2024.05.24 |


